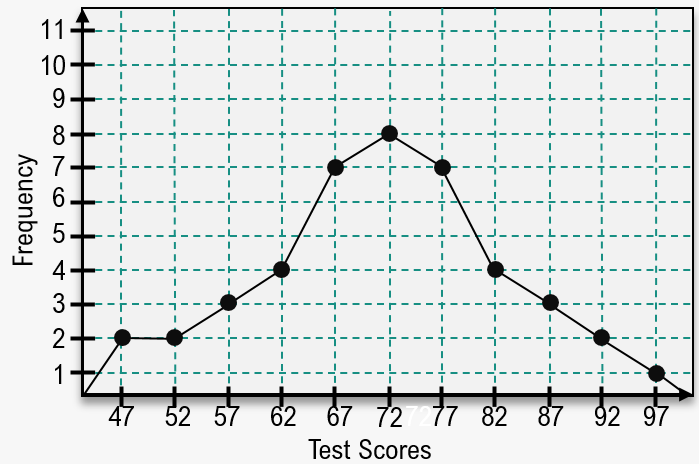
When displaying data in a frequency distribution, a histogram is often the go-to choice, but a frequency polygon is another effective option. A frequency polygon uses points connected by line segments to represent the same data as a histogram, allowing for a clear visualization of frequencies across different classes.
To create a frequency polygon, start by plotting points for each class based on their frequencies. For instance, if the frequency of the first class is six, you would plot a point at the corresponding x-axis position with a y-coordinate of six. Continue this process for each class, connecting the points with line segments to form the polygon. The y-axis for both the histogram and frequency polygon displays frequencies, while the x-axis is labeled with class midpoints, which can be calculated by averaging the lower and upper limits of each class. For example, for a class with a lower limit of 0 and an upper limit of 24, the midpoint is calculated as \(\frac{0 + 24}{2} = 12\).
Once the points are plotted and connected, the frequency polygon can be interpreted similarly to a histogram. Each point represents the frequency of individuals within a specific age range, rather than indicating an exact number of individuals at a specific age. This distinction is crucial to avoid confusion with line graphs.
Additionally, analyzing skewness in the data can be done using both histograms and frequency polygons. To determine skew, identify the peak of the distribution and observe the tails. A left tail indicates left skew, a right tail indicates right skew, and a balanced distribution suggests no skew. For example, if the peak occurs at a midpoint of 37 with a frequency of eight, and the tails are relatively equal on both sides, the data can be classified as not skewed.
Understanding how to create and interpret frequency polygons enhances your ability to analyze and present data effectively, providing a valuable tool for visualizing distributions.