

 05:54
05:54


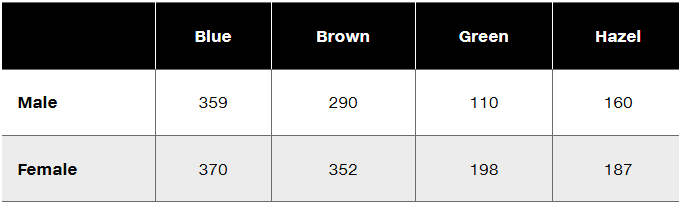
Textbook Question
Test for Normality For the hypothesis test described in Exercise 2, the sample sizes are n1 = 2208 and n2 = 1986 When using the F test with these data, is it correct to reason that there is no need to check for normality because both samples have sizes that are greater than 30?