Back
BackProblem 23a
The amino acid sequence of a portion of a polypeptide is
N...Cys-Pro-Ala-Met-Gly-His-Lys...C
What is the mRNA sequence encoding this polypeptide fragment? Use N to represent any nucleotide, Pu to represent a purine, and Py to represent a pyrimidine. Label the 5′ and 3′ ends of the mRNA.
Problem 23b
The amino acid sequence of a portion of a polypeptide is
N...Cys-Pro-Ala-Met-Gly-His-Lys...C
Give the DNA template and coding strand sequences corresponding to the mRNA. Use the N, Pu, and Py symbols as placeholders.
Problem 24a
Har Gobind Khorana and his colleagues performed numerous experiments translating synthetic mRNAs. In one experiment, an mRNA molecule with a repeating UG dinucleotide sequence was assembled and translated.
Write the sequence of this mRNA and give its polarity.
Problem 24b
Har Gobind Khorana and his colleagues performed numerous experiments translating synthetic mRNAs. In one experiment, an mRNA molecule with a repeating UG dinucleotide sequence was assembled and translated.
What is the sequence of the resulting polypeptide?
Problem 24c
Har Gobind Khorana and his colleagues performed numerous experiments translating synthetic mRNAs. In one experiment, an mRNA molecule with a repeating UG dinucleotide sequence was assembled and translated.
How did the polypeptide composition help confirm the triplet nature of the genetic code?
Problem 24d
Har Gobind Khorana and his colleagues performed numerous experiments translating synthetic mRNAs. In one experiment, an mRNA molecule with a repeating UG dinucleotide sequence was assembled and translated.
If the genetic code were a doublet code instead of a triplet code, how would the result of this experiment be different?
Problem 24e
Har Gobind Khorana and his colleagues performed numerous experiments translating synthetic mRNAs. In one experiment, an mRNA molecule with a repeating UG dinucleotide sequence was assembled and translated.
If the genetic code were overlapping rather than nonoverlapping, how would the result of this experiment be different?
Problem 25a
An experiment by Khorana and his colleagues translated a synthetic mRNA containing repeats of the trinucelotide UUG.
How many reading frames are possible in this mRNA?
Problem 25b
An experiment by Khorana and his colleagues translated a synthetic mRNA containing repeats of the trinucelotide UUG.
What is the result obtained from each reading frame?
Problem 25c
An experiment by Khorana and his colleagues translated a synthetic mRNA containing repeats of the trinucelotide UUG.
How does the result of this experiment help confirm the triplet nature of the genetic code?
Problem 26
The human β-globin polypeptide contains 146 amino acids. How many mRNA nucleotides are required to encode this polypeptide?
Problem 27
The mature mRNA transcribed from the human β-globin gene is considerably longer than the sequence needed to encode the 146–amino acid polypeptide. Give the names of three sequences located on the mature β-globin mRNA but not translated.
Problem 28
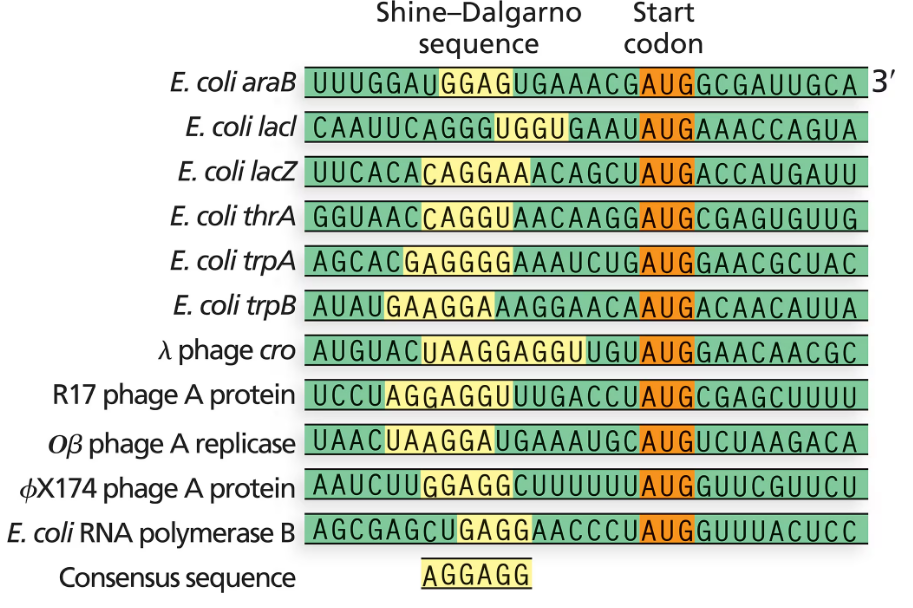
The following figure contains several examples of the Shine–Dalgarno sequence. Using the seven Shine–Dalgarno sequences from E. coli, determine the consensus sequence and describe its location relative to the start codon.
Problem 29a
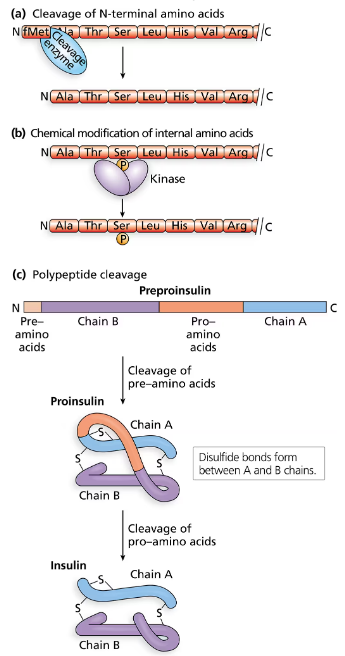
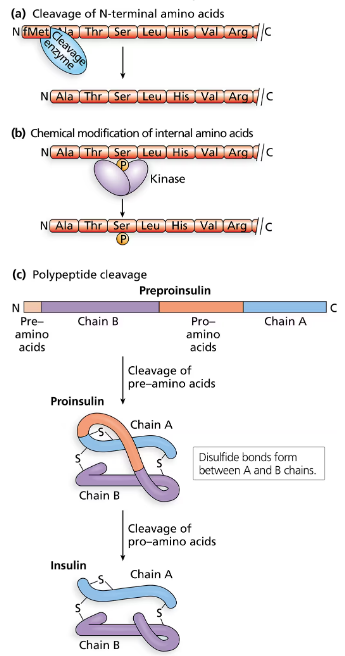
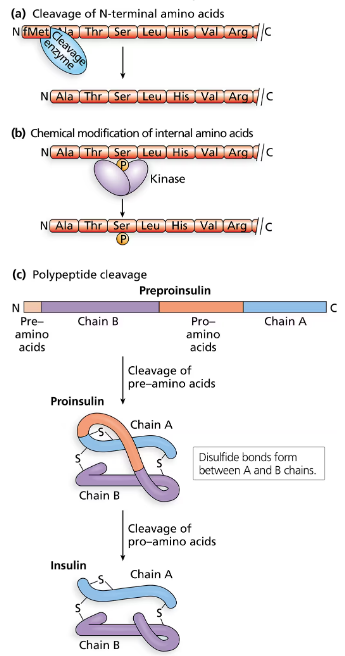
A research scientist is interested in producing human insulin in the bacterial species E. coli. Will the genetic code allow the production of human proteins from bacterial cells? Explain why or why not.
Problem 29b
Explain why it is not feasible to insert the entire human insulin gene into E. coli and anticipate the production of insulin.
Problem 29c
Recombinant human insulin (made by inserting human DNA encoding insulin into E. coli) is one of the most widely used recombinant pharmaceutical products in the world. What segments of the human insulin gene are used to create recombinant bacteria that produce human insulin?
Problem 30a
A DNA sequence encoding a five-amino acid polypeptide is given below.
...ACGGCAAGATCCCACCCTAATCAGACCGTACCATTCACCTCCT...
...TGCCGTTCTAGGGTGGGATTAGTCTGGCATGGTAAGTGGAGGA...
Locate the sequence encoding the five amino acids of the polypeptide, and identify the template and coding strands of DNA.
Problem 30b
A DNA sequence encoding a five-amino acid polypeptide is given below.
...ACGGCAAGATCCCACCCTAATCAGACCGTACCATTCACCTCCT...
...TGCCGTTCTAGGGTGGGATTAGTCTGGCATGGTAAGTGGAGGA...
Give the sequence and polarity of the mRNA encoding the polypeptide.
Problem 30c
A DNA sequence encoding a five-amino acid polypeptide is given below.
...ACGGCAAGATCCCACCCTAATCAGACCGTACCATTCACCTCCT...
...TGCCGTTCTAGGGTGGGATTAGTCTGGCATGGTAAGTGGAGGA...
Give the polypeptide sequence, and identify the N terminus and C terminus.
Problem 30d
A DNA sequence encoding a five-amino acid polypeptide is given below.
...ACGGCAAGATCCCACCCTAATCAGACCGTACCATTCACCTCCT...
...TGCCGTTCTAGGGTGGGATTAGTCTGGCATGGTAAGTGGAGGA...
Assuming the sequence above is a bacterial gene, identify the region encoding the Shine–Dalgarno sequence.
Problem 30e
A DNA sequence encoding a five-amino acid polypeptide is given below.
...ACGGCAAGATCCCACCCTAATCAGACCGTACCATTCACCTCCT...
...TGCCGTTCTAGGGTGGGATTAGTCTGGCATGGTAAGTGGAGGA...
What is the function of the Shine–Dalgarno sequence?
Problem 31a
A portion of the coding strand of DNA for a gene has the sequence
5′-...GGAGAGAATGAATCT...-3′
Write out the template DNA strand sequence and polarity as well as the mRNA sequence and polarity for this gene segment.
Problem 31b
A portion of the coding strand of DNA for a gene has the sequence
5′-...GGAGAGAATGAATCT...-3′
Assuming the mRNA is in the correct reading frame, write the amino acid sequence of the polypeptide using three-letter abbreviations and, separately, the amino acid sequence using one-letter abbreviations.
Problem 32a
A eukaryotic mRNA has the following sequence. The 5' cap is indicated in italics (CAP), and the 3' poly(A) tail is indicated by italicized adenines.
5′-CAPCCAAGCGUUACAUGUAUGGAGAGAAUGAAACUGAGGCUUGCCACGUUUGUUAAGCACCUAUGCUACCGAAAAAAAAAAAAAAAAAAAAAAAA-3′
Locate the start codon and stop codon in this sequence.
Problem 32b
A eukaryotic mRNA has the following sequence. The 5' cap is indicated in italics (CAP), and the 3' poly(A) tail is indicated by italicized adenines.
5′-CAPCCAAGCGUUACAUGUAUGGAGAGAAUGAAACUGAGGCUUGCCACGUUUGUUAAGCACCUAUGCUACCGAAAAAAAAAAAAAAAAAAAAAAAA-3′
Determine the amino acid sequence of the polypeptide produced from this mRNA. Write the sequence using the three-letter and one-letter abbreviations for amino acids.
Problem 33
Diagram a eukaryotic gene containing three exons and two introns, the pre-mRNA and mature mRNA transcript of the gene, and a partial polypeptide that contains the following sequences and features. Carefully align the nucleic acids, and locate each sequence or feature on the appropriate molecule.
a. The AG and GU dinucleotides corresponding to intron-exon junctions
b. The +1 nucleotide
c. The 5' UTR and the 3' UTR
d. The start codon sequence
e. A stop codon sequence
f. A codon sequence for the amino acids Gly-His-Arg at the end of exon 1 and a codon sequence for the amino acids Leu-Trp-Ala at the beginning of exon 2Problem 34
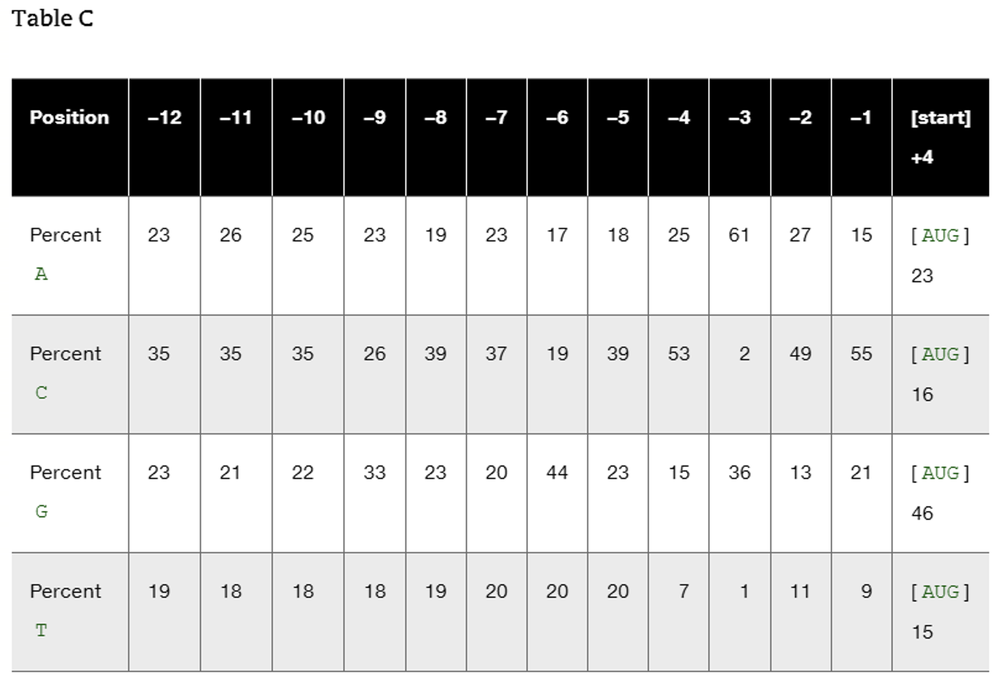
Table C contains DNA-sequence information compiled by Marilyn Kozak (1987). The data consist of the percentage of A, C, G, and T at each position among the 12 nucleotides preceding the start codon in 699 genes from various vertebrate species and at the first nucleotide after the start codon. (The start codon occupies positions +1 to +3 and the first nucleotide immediately after the start codon occupies position +4) Use the data to determine the consensus sequence for the 13 nucleotides ( -12 to -1 and +4) surrounding the start codon in vertebrate genes.
Problem 35a
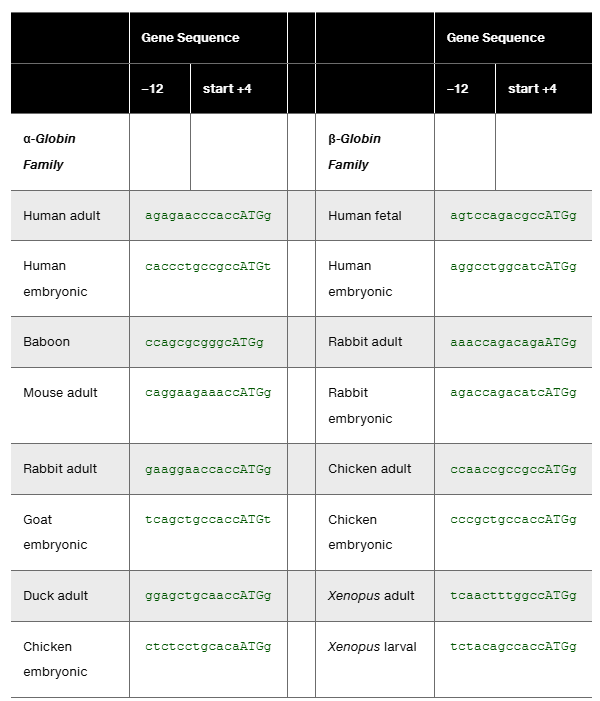
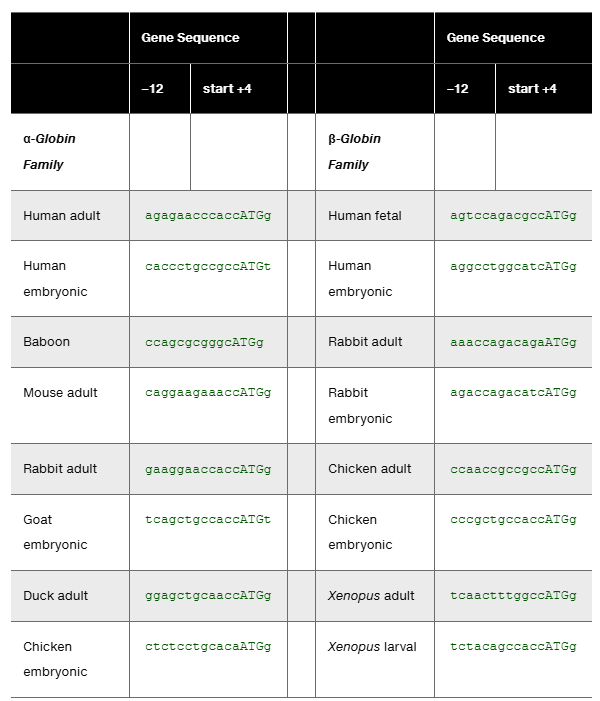
Table D lists α-globin and β-globin gene sequences for the 11 or 12 nucleotides preceding the start codon and the first nucleotide following the start codon (see Problem 34). The data are for 16 vertebrate globin genes reported by Kozak (1987). The sequences are written from -12 to +4 with the start codon sequence in capital letters. Use the data in this table to:
Determine the consensus sequence for the 16 selected α-globin and β-globin genes.
Problem 35b
Table D lists α-globin and β-globin gene sequences for the 11 or 12 nucleotides preceding the start codon and the first nucleotide following the start codon (see Problem 34). The data are for 16 vertebrate globin genes reported by Kozak (1987). The sequences are written from -12 to +4 with the start codon sequence in capital letters. Use the data in this table to:
Compare the consensus sequence for these globin genes to the consensus sequence derived from the larger study of 699 vertebrate genes in Problem 34.
Problem 36
The six nucleotides preceding the start codon and the first nucleotide after the start codon in eukaryotes exhibit strong sequence conservation as determined by the percentages of nucleotides in the to positions and the position (see Problem 34). Use the data given in the table for Problem 35 to determine the seven nucleotides that most commonly surround the start in vertebrates.